Calibración automática del desempeño con Modelo Rasch: evaluaciones justas sin depender del criterio del jefe

¿Te ha tocado “defender” una nota que, en el fondo, sabes que no es comparable con la del equipo de al lado?
El promedio te da un número cómodo… pero mezcla la dificultad de las competencias con el estilo personal de cada evaluador. El resultado: dos personas con la misma nota final pueden tener niveles de desempeño radicalmente distintos.
Este problema no nace solo en la fórmula de cálculo: muchas veces viene desde el diseño completo del sistema de evaluación de desempeño, especialmente cuando no hay criterios claros, escalas bien definidas ni mecanismos de comparación entre áreas.
El Modelo Rasch hace lo contrario: ajusta por “qué tan difícil era lo evaluado” y por “qué tan duro o blando evalúa cada jefe”. Resultado: menos suerte, más mérito medible… y decisiones de talento que sí se pueden explicar ante un comité, un directorio o un colaborador que pide respuestas.
En este artículo vas a entender qué es el Modelo Rasch, cómo funciona su versión multifacética para evaluaciones de desempeño, qué pasa operativamente cuando se implementa en una plataforma con IA, y cómo leer los resultados que genera. Todo explicado para profesionales de RRHH, no para estadísticos.
En este articulo:
Calibración Automática RASCH: ¿Cómo lograr evaluaciones de desempeño realmente justas?
Por qué el promedio falla al medir desempeño (y qué alternativa existe)

La mayoría de los sistemas de evaluación de desempeño siguen una lógica simple: definen una escala, piden a evaluadores que puntúen competencias, suman y promedian. Con ese número toman decisiones de bono, promoción, sucesión y desarrollo.
El problema es que detrás de ese promedio se esconden al menos tres distorsiones graves:
→ Las categorías de la escala no están equiespaciadas. El salto de “cumple parcialmente” a “cumple” no equivale al salto de “cumple” a “supera ampliamente”. El promedio trata esas distancias como si fueran iguales.
→ No todas las competencias tienen la misma dificultad. “Cumple plazos” no exige el mismo nivel que “anticipa riesgos complejos y actúa antes de que aparezcan”.
→ Cada evaluador tiene su propio “termómetro”. Hay líderes que rara vez dan la máxima calificación y otros que la entregan sin mayor filtro.
Este es uno de los problemas más frecuentes de los sesgos en la evaluación de desempeño: la nota no refleja solo el desempeño del colaborador, sino también el estilo, la severidad o la indulgencia de quien evalúa.
Las consecuencias no son solo técnicas: la investigación muestra que las personas que perciben el reconocimiento como justo y equitativo tienen cuatro veces más probabilidad de estar comprometidas. El compromiso, a su vez, se traduce en mayor productividad, menor rotación y menos incidentes de seguridad. Medir mal el desempeño es caro.
La alternativa existe. Se llama Modelo Rasch. Y cuando se combina con una buena calibración del desempeño, permite pasar de una discusión basada en percepciones a una conversación apoyada en datos comparables.
Descarga el ebook: la ilusión del promedio en evaluación de desempeño

Qué es el Modelo Rasch y por qué transforma la evaluación de desempeño

El Modelo Rasch es una familia de modelos estadísticos diseñada para medir constructos latentes: habilidades, competencias, actitudes, calidad de desempeño. Son cosas que no se ven directamente, pero se infieren a partir de respuestas a ítems o conductas observables.
Piensa en la “salud” de una persona. No la ves, pero la estimas con temperatura, presión, exámenes de sangre. Rasch hace algo similar con el desempeño:
→ Toma las calificaciones que recibe alguien en distintos ítems (competencias, conductas).
→ Considera la dificultad de cada ítem.
→ Considera la forma en que los evaluadores usan la escala.
→ Y a partir de ahí estima una medida de habilidad para cada persona, en una escala continua y comparable.
No le importa “cuántos puntos sacó” alguien, sino qué tan difícil fue conseguirlos. Esa diferencia cambia todo.
La relación habilidad–dificultad explicada para RRHH
En su versión básica, la lógica es intuitiva: la probabilidad de que una persona reciba una calificación alta en una competencia depende de la diferencia entre su nivel de habilidad y la dificultad de esa competencia.
Si la habilidad de la persona está muy por encima de la dificultad del ítem, es esperable que saque buena nota. Si está por debajo, es lógico que tenga dificultades.
Lo interesante es que el modelo estima ambas cosas al mismo tiempo: qué tan “difícil” es cada competencia y qué tan “hábil” es cada persona. Y lo hace en una misma escala. Eso permite afirmar, por ejemplo: “Esta persona tiene un nivel de desempeño que le permite dominar con seguridad competencias cuya dificultad es X; por encima de ese punto, empieza a fallar”.
La medición deja de ser una serie de casilleros llenos y pasa a ser un perfil continuo, comparable y defendible.
Rasch vs promedio: por qué dos personas con la misma nota no valen lo mismo
Imagina dos personas con el mismo promedio de 4,5 en una escala de 1 a 5:
→ Persona A: destaca en ítems que la mayoría considera muy difíciles; en los fáciles, también cumple.
→ Persona B: obtiene máximas solo en ítems fáciles; en los difíciles, se queda corta.
El promedio las trata como equivalentes. El Modelo Rasch las diferencia: ajusta hacia arriba el resultado de A y hacia abajo el de B, porque incorpora la dificultad real de lo que cada una logró.
Esto también muestra por qué la elección de la escala importa. Una escala mal diseñada puede amplificar las distorsiones del promedio; por eso conviene revisar si tu organización usa una escala tipo GRS, BARS u otro modelo más conductual para reducir sesgos en la evaluación de desempeño.
Algo similar ocurre con los evaluadores. Si una jefa es extremadamente severa, el modelo lo detecta. Si un jefe es sistemáticamente generoso, también. Y no solo lo detecta: ajusta las puntuaciones para que el resultado final no dependa de la fortuna de haber caído con un jefe u otro.
Es aquí donde entra la versión más potente del modelo para RRHH: el Modelo Rasch Multifacético.
Modelo Rasch Multifacético (MFRM): cómo corregir sesgos de evaluadores en desempeño

Las evaluaciones de desempeño reales no tienen un solo “examinador”. Hay jefes, pares, reportes, clientes internos, autoevaluaciones. Y cada grupo trae sus propios sesgos. Por eso, cuando una organización implementa una evaluación 360 grados, no basta con sumar opiniones: necesita entender cómo pesa cada fuente y cómo se comporta cada grupo evaluador.
El Modelo Rasch Multifacético (Many-Facet Rasch Model, MFRM) extiende la idea básica e incluye varias dimensiones —llamadas facetas— en un solo modelo.
Las tres facetas clave: persona, competencia y evaluador
En una evaluación de desempeño típica, las facetas principales son:
→ Persona evaluada: el colaborador cuyo desempeño queremos medir.
→ Ítem (competencia / conducta / criterio): lo que está siendo evaluado. Por ejemplo: “cumple plazos”, “influye en otros”, “anticipa riesgos”.
→ Evaluador: quien otorga la calificación. Jefe directo, par, cliente interno, reporte.
El modelo estima parámetros para cada elemento: nivel de desempeño de la persona, dificultad de cada competencia, y severidad o generosidad de cada evaluador. Todo en una misma escala.
Cómo se corrige la severidad del evaluador sin conflicto
Pensemos en dos líderes:
→ Jefa A: rara vez da la máxima nota; considera que “siempre hay espacio para mejorar”.
→ Jefe B: valora mantener alta la moral, por lo que sus evaluaciones tienden a ser muy altas.
En términos de data, la distribución de notas de A se concentra en la parte baja/media de la escala, y la de B en la parte alta.
El MFRM calcula un coeficiente de severidad para cada evaluador. Luego, recalibra las respuestas como si todos hubieran evaluado con un “termómetro estándar”.
El resultado práctico es concreto: una nota 4 dada por la Jefa A puede tener el mismo valor —o más— que una nota 5 dada por el Jefe B. Los colaboradores dejan de estar “castigados o premiados” por el estilo personal de su jefe.
Para RRHH, esto significa algo muy claro: las decisiones de talento se basan en mérito real, no en quién te evaluó.
Cómo funciona la calibración automática Rasch paso a paso

Ahora que la lógica está clara, vamos a la operativa. ¿Qué tiene que ocurrir en tu organización para que la calibración Rasch funcione de forma automática?
Del dato granular al modelado estadístico
La materia prima son las respuestas individuales: calificaciones por competencia y por objetivo, separadas por evaluador (jefe, par, autoevaluación, etc.), con información de contexto mínima como área, cargo y tipo de contrato. En especial, cuando trabajas con evaluación de desempeño por competencias, el dato granular es clave: no basta con saber la nota final, sino qué competencia fue evaluada, con qué criterio y por quién.
Aquí hay una primera decisión clave: no basta con registrar el resultado global (“nota final 4,3”). El modelo necesita ver qué pasó en cada ítem para poder estimar dificultad, severidad y habilidad. En plataformas integrales de desempeño, esta información se capta automáticamente en el flujo natural de evaluación, sin trabajo extra para RRHH.
Con los datos listos, un software especializado ajusta el Modelo Rasch Multifacético a las respuestas. El modelo se construye definiendo qué facetas se van a incluir: persona, competencia, evaluador… y eventualmente otras como unidad de negocio o tipo de proyecto.
El resultado de esta fase es un conjunto de estimaciones: habilidad calibrada por persona, dificultad calibrada por ítem, severidad calibrada por evaluador, y estadísticos de ajuste que dicen qué tan bien se comportan los datos.
De la escala logit a resultados que RRHH puede usar
El modelo trabaja en una escala técnica llamada logit, donde las distancias sí son iguales. Eso es ideal para el análisis, pero poco amigable para comunicar en la organización.
Por eso, el siguiente paso es re-escalar los resultados a métricas conocidas: 0–100 puntos, escalas 1–5 o 1–7 verdaderamente equiespaciadas, o rangos interpretativos (por ejemplo: por debajo de 40 = riesgo; 40–70 = desempeño adecuado; sobre 70 = alto desempeño).
Aquí es donde muchas empresas fallan: generan resultados técnicos que luego nadie entiende. Cuando este re-escalamiento está embebido en una plataforma como parte del flujo, el usuario final nunca ve logits; ve un resultado claro, con contexto y con explicaciones accionables.
La calibración no es el final; es el inicio de mejores decisiones. Los resultados alimentan matrices de talento como la Nine Box, que combina desempeño calibrado con potencial, reportes por jefatura, área y cargo que permiten comparar manzanas con manzanas, y planes de desarrollo automáticos que se disparan según brechas detectadas en competencias específicas.
La clave está en que el usuario no tenga que “entender Rasch”. Solo necesita sentirse tranquilo de que la base numérica es justa y consistente.
Cómo interpretar los resultados Rasch: Wright Map, severidad y ajuste
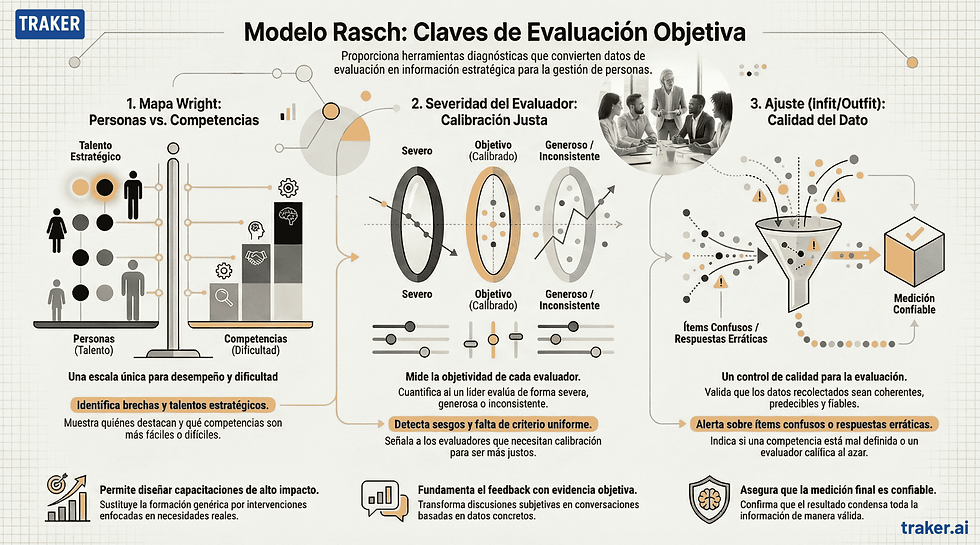
Una de las grandes ventajas del Modelo Rasch es que no solo da un número final: abre la caja negra de la evaluación. Tres herramientas lo hacen posible.
Wright Map: cómo visualizar talento y brechas en una sola escala
El Wright Map (o mapa de personas e ítems) es una visualización que pone en una misma escala vertical a los colaboradores ordenados por nivel de desempeño (a la izquierda) y a las competencias ordenadas por dificultad (a la derecha).
Esto permite ver de un vistazo: quiénes son las personas con desempeño más alto y más bajo, qué competencias resultan más fáciles o más difíciles para la organización, y en qué rangos de dificultad falta “cobertura” (si casi todas las competencias son muy fáciles o muy difíciles, el instrumento deja de discriminar bien).
Desde la gestión de RRHH, el mapa se vuelve una herramienta estratégica. Si el área de Operaciones tiene una medida promedio inferior a la de Ventas, el Wright Map te ayuda a identificar qué competencias concretas marcan la diferencia. En lugar de lanzar una capacitación genérica, puedes diseñar intervenciones específicas sobre esas conductas.
Índice de severidad del evaluador: qué dice y cómo usarlo
El modelo entrega una medida de severidad para cada evaluador, con su error estándar y su intervalo de confianza.
Con esto puedes detectar jefes extremadamente severos o generosos, ver si ciertos evaluadores son inconsistentes a lo largo del tiempo (por ejemplo, cambian de criterio sin explicación), y diseñar formaciones específicas para calibrar criterios y mejorar la calidad del feedback.
En lugar de discutir “a quién le crees más”, tienes evidencia objetiva de cómo evalúa cada persona.
Infit y Outfit: el control de calidad de tus datos de evaluación
Los indicadores de ajuste (infit y outfit) señalan si un ítem se comporta de forma extraña (por ejemplo, una competencia mal definida que genera respuestas impredecibles), si un evaluador califica de manera errática, o si un colaborador responde de forma incoherente marcando extremos sin patrón.
En estudios de evaluación de desempeño, el uso del MFRM ha permitido identificar ítems poco claros, rúbricas mal diseñadas y evaluadores que distorsionan el resultado.
Cuando estos indicadores están dentro de rangos aceptables, puedes considerar que la medida final es una “estadística suficiente”: un número que condensa toda la información relevante de manera fiable.
Descarga la Guía visual: por qué promediar el desempeño genera injusticia

Calibración automática vs calibración por comité: diferencias clave
Si ya conoces las sesiones de calibración —donde líderes se reúnen en una sala a “nivelar” las evaluaciones de sus equipos— probablemente te preguntas cómo se diferencia la calibración Rasch de ese proceso.
La calibración por comité es valiosa: genera conversación, obliga a argumentar y crea consenso. Pero tiene limitaciones estructurales. Depende del criterio subjetivo de quienes están en la sala, se ve afectada por dinámicas de poder (el jefe con más antigüedad tiende a dominar la discusión), no escala bien cuando la organización tiene cientos o miles de evaluaciones, y no puede corregir matemáticamente la severidad de un evaluador —solo puede discutirla.
La calibración automática con Rasch opera en un plano distinto. No reemplaza la conversación; la fundamenta. Antes de que el comité se siente, los datos ya están ajustados por dificultad de competencia y severidad del evaluador. El comité puede entonces enfocarse en los casos atípicos —los que el modelo señala como fuera de patrón— en lugar de revisar cientos de notas una por una.
El escenario ideal combina ambos enfoques: calibración estadística automática como base objetiva, y sesión de calibración por comité como espacio de validación y decisión humana. Si quieres bajar esto a una práctica operativa, esta guía de calibración del desempeño paso a paso muestra cómo preparar la sesión, qué actores deben participar y cómo documentar decisiones sin convertir la calibración en una negociación política.
Calibración automática en la práctica: cómo lo implementa un software de desempeño con IA

Hasta aquí hemos hablado de estadística. Pero la verdadera transformación ocurre cuando esto se convierte en flujo de trabajo real.
Plataformas como TRAKER están diseñadas para llevar este tipo de lógica a la operación diaria de la gestión del desempeño: un software de evaluación de desempeño con IA que define objetivos, mide competencias, calibra resultados, sugiere feedback y construye planes de desarrollo, todo dentro de un mismo sistema.
Cómo se ve para RRHH y líderes
En lugar de cuatro excels, tres formularios y dos plataformas distintas que no se hablan entre sí, tienes un flujo único y automatizado donde las evaluaciones llegan a tiempo y sin persecución manual, la calibración se ejecuta en segundo plano con IA y Rasch, los reportes aparecen listos con medidas ya ajustadas por dificultad de competencia y severidad del evaluador, y las comparaciones entre equipos y áreas son realmente justas.
Beneficios tangibles de integrar Rasch en un software de desempeño
Al integrar el modelo en una plataforma, la empresa obtiene:
→ Mejora del desempeño con IA en segundos: la plataforma detecta problemas en objetivos, feedback y competencias, y propone ajustes antes de que se conviertan en conflictos.
→ Eliminación de procesos manuales: la recolección, consolidación y análisis de datos se automatizan. RRHH deja de ser “policía de formularios” y pasa a ser socio estratégico.
→ Feedback continuo y calibrado: la IA ayuda a que los comentarios sean más específicos, útiles y alineados con las brechas reales de cada persona.
→ Evaluaciones 360° y Ninebox objetivas: la matriz de talento refleja datos ajustados, no percepciones infladas o castigadas por el estilo de un jefe.
→ Planes de desarrollo en tiempo real: a partir de las brechas que muestra el modelo, se generan acciones concretas y medibles para cada colaborador.
→ Objetivos conectados con la estrategia del negocio: la IA detecta objetivos mal redactados o poco desafiantes y sugiere mejoras.
En resumen: el Modelo Rasch deja de ser un paper académico y se convierte en una ventaja competitiva, porque permite construir un sistema de gestión del desempeño que la gente percibe como justo, consistente y alineado con el negocio.
Conclusión: de promediar a calibrar — el salto que transforma la gestión del talento
La mayoría de las empresas dice creer en el mérito. Pero mientras sigan promediando escalas subjetivas, estarán tomando decisiones críticas con una base frágil.
El Modelo Rasch y su versión multifacética ofrecen algo muy valioso: una forma de transformar opiniones dispersas en medidas objetivas y comparables, un método para corregir sesgos de evaluadores sin culpar a nadie apoyándose en datos, y una base sólida para conversar sobre talento con jefes, comités de personas y directorios.
Sumado a la inteligencia artificial, permite pasar de un esquema de evaluaciones que genera desconfianza a un sistema que mide con más justicia, explica mejor las decisiones, y convierte el feedback en una conversación que impulsa el desempeño —no en un trámite anual.
Si estás en RRHH, si lideras equipos o si estás impulsando un cambio en la gestión del talento en tu organización, este es el momento de dar el salto: dejar de promediar y empezar a calibrar.
Preguntas frecuentes sobre calibración automática con Modelo Rasch
¿Esto significa que la IA o la estadística “corrigen” al jefe?
No se trata de dejar al jefe fuera de juego, sino de corregir los sesgos sistemáticos que afectan la comparabilidad. El criterio del líder sigue siendo clave, pero ahora se integra en un sistema que detecta si alguien evalúa de forma muy distinta al resto, ajusta las puntuaciones para que todos jueguen con la misma vara, y entrega feedback al evaluador sobre su propio estilo.
¿Necesito millones de datos para aplicar Rasch?
No. Los modelos Rasch se han utilizado con muestras relativamente pequeñas en ámbitos como educación, música o medicina, siempre que haya suficiente información por ítem y evaluador. Lo importante es tener datos a nivel de ítem, diseñar bien el instrumento (competencias, conductas, escalas), y mantener cierta continuidad en los evaluadores.
¿Es compatible con evaluaciones 90°, 180°, 270° y 360°?
Sí. El MFRM es especialmente útil en entornos multi-evaluador. Puede incluir distintas facetas (jefes, pares, reportes, clientes), permite analizar si ciertos grupos son más severos o generosos, y ajusta las medidas para que todos los puntos de vista se integren en una escala común.
¿Qué pasa con los objetivos numéricos? ¿También se calibran?
Los objetivos cuantitativos tienen otra lógica, pero pueden integrarse en el modelo si se transforman en categorías (por ejemplo, niveles de cumplimiento). Otra alternativa es medir objetivos en un módulo específico apoyado en IA (para revisar redacción, dificultad, alineamiento estratégico) y utilizar Rasch principalmente para la parte de competencias y conductas observables. Para ese caso, conviene trabajar con un módulo de objetivos y metas que ayude a revisar redacción, dificultad, alineamiento estratégico y seguimiento antes de llegar a la evaluación final.
En la práctica, muchas plataformas integran ambos mundos: IA para objetivos, Rasch para calibración de competencias y feedback.
¿Necesito un equipo de estadísticos internos?
No necesariamente. Hay tres opciones: un equipo interno de analítica que modele Rasch con R u otro software, consultores externos que hagan el primer diseño y acompañen los ciclos iniciales, o plataformas especializadas que traen el modelo embebido en su motor de IA y analítica, entregando resultados listos para usar. Lo relevante es que RRHH entienda el concepto y pueda explicar por qué la medición es más justa, aunque no programe el modelo.
¿Cuál es la diferencia entre calibración por comité y calibración Rasch?
La calibración por comité se basa en discusión grupal para nivelar criterios; es subjetiva pero genera consenso. La calibración Rasch es estadística: ajusta matemáticamente por dificultad y severidad. Lo ideal es combinar ambas: Rasch genera la base objetiva, el comité valida y decide los casos atípicos.
¿Cuáles son las limitaciones del Modelo Rasch en evaluación de desempeño?
El modelo asume unidimensionalidad (que se está midiendo un solo constructo latente), lo cual puede ser una simplificación en evaluaciones que mezclan competencias muy distintas. También requiere datos a nivel de ítem —si tu sistema solo registra la nota global, no hay materia prima para el modelado. Y necesita un diseño de instrumento razonable: si las competencias están mal definidas o la escala está mal diseñada, Rasch no puede corregir un problema de origen. Dicho esto, estas limitaciones son gestionables cuando la implementación se hace dentro de una plataforma que controla el diseño del instrumento.
¿Cómo se lee un Wright Map en RRHH?
El Wright Map pone personas y competencias en la misma escala vertical. A la izquierda ves a los colaboradores ordenados por nivel calibrado de desempeño; a la derecha, las competencias ordenadas por dificultad. Si una persona está a la misma altura que una competencia, tiene aproximadamente 50% de probabilidad de dominarla. Los que están por encima la dominan con holgura; los que están por debajo necesitan desarrollo en esa área. Es la herramienta más potente para diseñar intervenciones de desarrollo con precisión quirúrgica.