Entrenamiento de evaluadores: RET, FOR y BO para evaluar sin sesgos

¿Cansado de que dos jefes miren al mismo equipo y lleguen a veredictos opuestos?
Cuando no hay estándar ni evidencia acumulada durante el ciclo, el cerebro rellena los vacíos con atajos. La calibración se vuelve una pelea y RRHH termina arbitrando en lugar de gestionar.
Este artículo explica tres métodos de entrenamiento complementarios —RET, FOR y BO— que atacan causas distintas del sesgo. Encontrarás qué hace cada uno, cómo se comparan, cuál aplicar primero según tu situación y un plan concreto de 30 a 60 días para implementarlos sin burocracia.
Antes de elegir entre RET, FOR o BO, conviene distinguir si el problema viene de sesgos individuales, falta de evidencia o criterios poco comparables. Si quieres profundizar en esa base, puedes revisar esta guía sobre cómo evaluar con evidencia y reducir sesgos del jefe.
En este articulo:
Por qué los sesgos aparecen incluso en líderes bien intencionados

La evaluación del desempeño mezcla tres elementos explosivos: juicio humano, memoria selectiva y consecuencias reales —aumentos, promociones, reputación—. Esa combinación abre sistemáticamente la puerta a errores del evaluador que ocurren en piloto automático, independientemente de la competencia o las buenas intenciones del líder.
Los errores más frecuentes documentados en la literatura sobre evaluación de desempeño son:
→ Halo: una sola fortaleza tapa todo lo demás.
→ Recencia: pesa demasiado lo último que ocurrió en el ciclo.
→ Primacía: pesa demasiado la primera impresión.
→ Leniencia / Severidad: el evaluador califica sistemáticamente alto o sistemáticamente bajo.
→ Tendencia central: la mayoría de las personas queda en rango promedio sin discriminación real.
→ Similitud / Afinidad: "me recuerda a mí", por lo tanto lo veo mejor.
La trampa es creer que la intención de ser justo basta. No basta. La justicia evaluativa no es una disposición: es un diseño. Ahí entran RET, FOR y BO.
El beneficio operativo oculto: menos calibración, menos desgaste
Entrenar a los evaluadores no solo sube la calidad ética del proceso. También reduce costos operativos concretos:
→ menos tiempo discutiendo notas sin evidencia en sesiones de calibración.
→ menos retrabajo para RRHH corrigiendo incoherencias entre áreas.
→ menos reclamos de "esto es injusto" de parte de los evaluados.
→ más confianza en los resultados del Nine Box y en las decisiones de talento derivadas.
Décadas de investigación sobre entrenamiento de evaluadores muestran mejoras sostenidas en precisión, consistencia y criterios compartidos.
El método con mayor evidencia acumulada en esa dirección es el Frame of Reference Training (FOR). Por eso, cuando el dolor principal es la incoherencia entre evaluadores, el entrenamiento no debería quedar como un taller aislado: debe conectarse con un proceso formal de calibración del desempeño.
Métodos de entrenamiento para evaluadores: RET, FOR y BO

Los tres métodos atacan causas distintas del sesgo y son complementarios. Usarlos de forma aislada da resultados parciales; combinados de forma secuencial, generan un sistema robusto de evaluación basada en evidencia.
RET (Rater Error Training): qué es y cuándo aplicarlo

Qué es: RET enseña a reconocer los errores típicos del evaluador —halo, leniencia, recencia, similitud— y a evitar las trampas mentales asociadas. Su objetivo es hacer consciente lo que antes ocurría en piloto automático.
Cómo se entrena normalmente:
→ explicación clara de los sesgos y por qué ocurren.
→ videos o casos cortos donde el sesgo se ve en acción.
→ discusión guiada: "¿Dónde me pasa esto a mí?".
→ micro-técnicas de corrección: checklist previo, pausas, contraste con evidencia objetiva.
Lo que RET hace bien: sube el conocimiento sobre sesgos y genera que el líder se examine a sí mismo antes de evaluar.
Su límite importante: RET mejora la conciencia, pero no garantiza que el líder aplique estándares correctos ni que observe mejor durante el año. Por eso se considera el punto de entrada, no la solución completa.
Cuándo RET es ideal:
→ cuando estás comenzando y necesitas un idioma común sobre errores.
→ cuando detectas sesgos evidentes (halo o leniencia) y quieres un shock de realidad rápido.
→ cuando vas a lanzar una evaluación 360° y necesitas higiene mínima antes de abrir el proceso a muchos evaluadores.
FOR (Frame of Reference Training): cómo crear un estándar compartido entre evaluadores

Qué es: FOR crea un marco común para que distintos evaluadores entiendan lo mismo por "buen desempeño" y califiquen con criterios comparables. Su objetivo es que dos líderes vean la misma conducta y la ubiquen en el mismo nivel —o muy cerca.
Por qué suele ser el más efectivo: la evidencia acumulada, incluidos meta-análisis, muestra que FOR es el método con mayor impacto sostenido en precisión y consistencia entre evaluadores.
Cómo se ve un FOR bien hecho:
Paso 1: Definir qué significa cada nivel
No basta con "cumple" o "excede". Hay que bajar a conducta observable. Qué hace concretamente alguien sobresaliente, alguien en nivel esperado y alguien por debajo de lo esperado en cada competencia o meta. En la práctica, esta definición depende mucho de la escala que uses. Por eso también conviene revisar cuándo usar escalas GRS o BARS para reducir sesgos en evaluación de desempeño.
Paso 2: Practicar con casos (calificar, comparar, ajustar)
Todos los evaluadores califican el mismo caso. Se comparan las notas. Se discute evidencia conductual —no opiniones—. Se ajusta el estándar colectivamente.
Paso 3: Feedback inmediato sobre el criterio
El líder no solo aprende la teoría: aprende calibrando su criterio personal contra el estándar definido grupalmente.
Resultado típico cuando FOR se instala de verdad: baja la variabilidad absurda entre líderes, sube la comparabilidad entre áreas y la calibración formal se vuelve más corta y menos emocional.
Cuándo FOR es ideal:
→ cuando tu problema central es incoherencia: cada jefe evalúa según su propio criterio.
→ cuando el Nine Box pierde credibilidad por diferencias sistemáticas entre evaluadores.
→ cuando RRHH termina arbitrando decisiones más de lo que gestiona talento.
BO (Behavioral Observation Training): cómo observar y registrar durante el ciclo

Qué es: BO entrena la capacidad de observar desempeño y registrarlo durante el ciclo para no depender de la memoria al cierre. Su objetivo es llegar a la evaluación con evidencia fresca y concreta, no con sensaciones.
Sesgos que BO ataca con más fuerza:
→ errores de memoria: recencia y primacía.
→ distorsiones por falta de datos ("no me acuerdo bien, pero...").
→ sesgos de contexto: un conflicto reciente contamina la lectura de todo el ciclo.
Cómo se entrena normalmente:
→ técnicas para registrar incidentes críticos positivos y negativos.
→ cómo tomar notas breves, útiles y no invasivas.
→ cómo separar conducta observable de interpretación subjetiva.
→ cómo usar registros de desempeño sin convertirlos en burocracia.
Evidencia detrás: la investigación clásica sobre clasificación de métodos de entrenamiento de evaluadores muestra que BO puede mejorar la precisión observacional porque fortalece la base de información con la que se evalúa, reduciendo la dependencia de la memoria.
Cuándo BO es ideal:
→ cuando los líderes evalúan de memoria y eso genera peleas en calibración.
→ cuando el feedback llega tarde, impreciso o solo cuando hay problemas graves.
→ cuando quieres transitar de evaluación anual a seguimiento continuo.
Descarga el ebook: cómo evaluar desempeño sin sesgos ni memoria.


RET vs FOR vs BO: comparación por profundidad, impacto y casos de uso

Nivel de profundidad
→ RET: superficial. Crea conciencia de sesgos, pero no asegura cambio de hábito ni aplicación de estándares correctos.
→ FOR: profundo. Enseña a aplicar estándares comunes; mejora consistencia y precisión de forma sostenida.
→ BO: muy profundo. Mejora la observación y la calidad de la evidencia acumulada a lo largo del ciclo.
Errores que busca minimizar
→ RET: errores generales —halo, recencia, contraste, similitud—.
→ FOR: errores de interpretación y consistencia entre evaluadores.
→ BO: errores de memoria y sesgos derivados de falta de datos objetivos.
Estrategia de entrenamiento
→ RET: explicar sesgos, mostrar ejemplos en casos, discutir correcciones individuales.
→ FOR: definir estándares conductuales + ejercicios de evaluación comparativa con feedback grupal.
→ BO: enseñar a observar, registrar y usar evidencia conductual como rutina del ciclo.
Impacto esperado en precisión
→ RET: aumenta conciencia; no siempre se traduce en mayor precisión sostenida.
→ FOR: aumenta precisión al alinear los criterios de evaluación entre líderes.
→ BO: aumenta precisión al reducir distorsiones de memoria y dependencia del contexto reciente.
Duración del entrenamiento
→ RET: 60 a 90 minutos si se hace práctico.
→ FOR: 2 a 4 horas, según la cantidad de dimensiones o competencias a calibrar.
→ BO: 60 a 120 minutos de taller + rutina semanal mínima de mantenimiento.
Cuando el problema ya no es solo entrenar, sino detectar patrones de sesgo entre evaluadores, conviene complementar estos métodos con análisis de datos. En ese caso, puede ser útil revisar cómo funciona la calibración automática del desempeño con IA.
Descarga la guía visual: tres entrenamientos para evaluar sin sesgos.

¿Cuál entrenamiento aplicar primero? Guía por síntomas organizacionales
La elección del punto de partida depende del síntoma dominante en tu proceso actual:
"La gente no entiende sus propios errores al evaluar"
→ Empieza con RET.
→ Objetivo: higiene mínima y vocabulario común sobre sesgos.
"Cada jefe evalúa según su propio criterio"
→ Prioriza FOR.
→ Objetivo: un estándar compartido que haga comparables las calificaciones.
"
En calibración todos discuten porque no hay evidencia"
→ Implementa BO, idealmente combinado con FOR.
→ Objetivo: dejar de evaluar desde memoria y construir evidencia durante el ciclo.
En la práctica, el combo más robusto es:
→ RET como base rápida de conciencia.
→ FOR como columna vertebral de criterio común.
→ BO como músculo diario de evidencia real.
Nota: Ningún entrenamiento reemplaza al otro. RET sin FOR no da precisión. FOR sin BO depende igualmente de la memoria al cierre. Los tres se potencian cuando se implementan en secuencia.
Plan de implementación en 30–60 días: RET, FOR y BO por fases
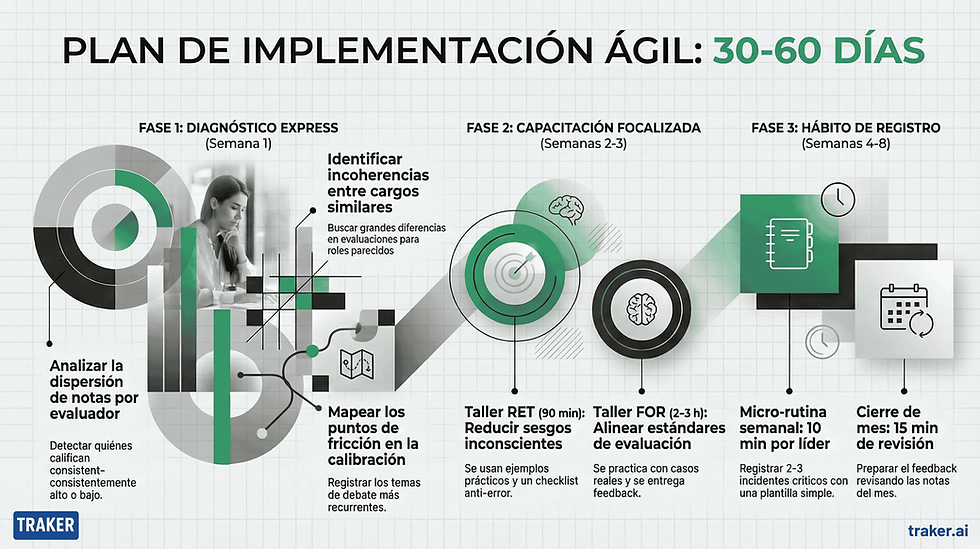
Semana 1: diagnóstico de dispersión e incoherencias entre evaluadores
Antes de entrenar, identifica dónde está el problema real:
→ revisa la dispersión de notas por evaluador: ¿quién pone consistentemente alto? ¿quién aplana todo al promedio?
→ detecta áreas con incoherencia: misma familia de cargos, notas muy distintas entre jefes.
→ mapea los "momentos de pelea" recurrentes en calibración: qué temas se repiten ciclo tras ciclo.
Este diagnóstico define cuánto peso darle a cada entrenamiento y en qué orden.
Semanas 2–3: taller RET + FOR (corto, alto impacto)
→ RET en 60 a 90 minutos: sesgos + ejemplos reales del ciclo + checklist anti-error personalizado.
→ FOR en 2 a 3 horas: definición de estándares conductuales + casos prácticos + calibración grupal + feedback inmediato sobre el criterio aplicado.
Condición crítica para FOR online: debe haber práctica con casos y feedback en tiempo real. Un FOR sin práctica es solo una presentación y pierde la mayor parte de su impacto.
Semanas 4–8: BO como hábito de registro continuo
→ 10 minutos a la semana por líder para registrar 2 a 3 incidentes críticos observados.
→ plantilla simple: conducta observada, contexto, impacto, evidencia disponible.
→ cierre de mes: 15 minutos para revisar notas acumuladas y preparar el feedback del período.
BO no se sostiene con un taller anual. Se sostiene con hábito, seguimiento y una estructura mínima que no genere fricción.
Cómo medir el impacto del entrenamiento de evaluadores
Si no lo mides, solo lo sientes. Y eso se presta para autoengaño en ambas direcciones. Las métricas prácticas para evaluar si los entrenamientos funcionaron son:
→ Consistencia entre evaluadores: ¿se acercan más las notas para casos similares entre distintos jefes?
→ Distribución por líder: ¿sigue existiendo el que pone todo en 5 o el que aplana todo?
→ Volumen de ajustes en calibración: ¿se redujo el retrabajo y el tiempo de sesión?
→ Calidad de la evidencia: ¿los evaluadores citan conductas observables, no adjetivos?
→ Percepción de justicia del proceso: una pregunta corta post-ciclo puede bastar como indicador de tendencia.
Referencia de línea base: toma estas métricas antes de implementar los entrenamientos. La comparación ciclo a ciclo es más útil que cualquier benchmark externo.
Conclusión: la evaluación justa no se improvisa, se diseña
Si tu proceso de calibración se siente pesado, interminable, político o a ratos injusto, el problema rara vez es la buena voluntad de los líderes. El problema es la ausencia de una estructura que:
→ haga conscientes los sesgos que operan en piloto automático (RET).
→ alinee los criterios entre evaluadores para que el mismo desempeño reciba calificaciones comparables (FOR).
→ convierta la memoria en evidencia acumulada durante el ciclo, no reconstruida al cierre (BO).
Aplicados como estrategias complementarias y en secuencia, estos tres métodos generan un cambio concreto donde más importa: conversaciones de feedback más precisas, decisiones de talento más defendibles, menos fricción entre líderes y una cultura donde el desempeño se gestiona durante todo el ciclo, no solo se califica al final.
Preguntas frecuentes sobre entrenamiento de evaluadores
¿Cuánto tiempo dura cada entrenamiento (RET, FOR y BO)?
→ RET: 60 a 90 minutos si se hace práctico, con casos y discusión.
→ FOR: 2 a 4 horas, según la cantidad de dimensiones o competencias a calibrar.
→ BO: 60 a 120 minutos de taller inicial + rutina semanal mínima de 10 minutos por líder.
¿Se puede hacer online el entrenamiento de evaluadores?
Sí, con una condición crítica: debe haber práctica con casos reales y feedback en tiempo real, especialmente en FOR. Un entrenamiento online sin ejercicio práctico reduce el impacto de FOR a casi nulo —pasa a ser solo una presentación—. RET y BO se adaptan mejor al formato online.
¿Funciona este entrenamiento en evaluaciones 360°?
Funciona especialmente bien, porque en una evaluación 360° se multiplican los evaluadores y con eso se multiplica también la variabilidad de criterios. FOR ayuda a que un nivel "4" signifique algo equivalente entre un par, un jefe y un colaborador. RET prepara a evaluadores no habituales para reconocer sus propios sesgos antes de calificar.
¿Cada cuánto hay que repetir RET, FOR y BO?
→ RET: refresco anual corto (30 a 45 minutos) antes de cada ciclo de evaluación.
→ FOR: refresco por ciclo, especialmente si cambian competencias, metas o escalas. Incluir micro-casos en la sesión de calibración puede reemplazar un FOR completo en ciclos subsiguientes.
→ BO: no se sostiene con talleres anuales. Se sostiene con rutina semanal y seguimiento de líderes. El hábito es el entrenamiento.
¿El entrenamiento de evaluadores reemplaza la calibración?
No. La vuelve más corta, más objetiva y significativamente menos desgastante. Calibración sin entrenamiento previo es apagar incendios. Calibración con evaluadores entrenados es mantenimiento preventivo: mismos participantes, menor fricción, decisiones más defendibles.